Finding a typo in Fourth Wing using AI
Should we be using AI to help edit books?
/ 5 min read
Table of Contents
Grab your copy of Fourth Wing. I’ll wait. Near the start of chapter 10 you’ll see a blink-and-you-miss-it typo in a last name:
…because you made friends with Barlowe and Siefert…
That’s not how you spell “Siefert” in the book though: it’s S-e-i, not S-i-e.
So who cares?
It’s a typo, big deal. But it raises some interesting questions. Can AI tools reliably catch inconsistencies that slip past (human) editors and proofreaders? How do you even surface a one-letter spelling flip buried in a ~150,000-word novel? And once you find it, what else can you learn about a book by treating character nicknames as structured data?
Discovery
I stumbled upon this while trying to gather all the ways characters refer to each other in novels, an important part of interactive fan fiction. These nicknames / epithets / what I’ll call appellations are very specific and something authors clearly spend a lot of time on:
Xaden → Violet
- “Sorrengail” given name ch 1–33
Surname-only. Distancing, impersonal.
- “Violence” epithet → pet name ch 9–38
Starts as a mocking taunt during sparring; reclassified as a term of endearment by chapter 19.
- “Violet” given name ch 27–39
Her actual first name. Only appears once he’s emotionally invested.
- “Vi” diminutive ch 32, 38
Used exactly twice, both times in moments of extreme vulnerability.
Feyre → Tamlin
- “the beast” epithet ch 4–6
Before she knows him. Pure fear and unfamiliarity.
- “the golden-haired one” epithet ch 6–7
Transitional. She sees him in human form but doesn’t know his name.
- “Tamlin” given name ch 7–46
Once named, used consistently throughout the book.
- “the High Lord” formal title ch 15–28
Layers onto the given name after she learns his political status.
- “Tam” diminutive ch 18–31
Intimate moments only.
Killian → Meryn
- “kitten” pet name ch 1–57
Present from the very first chapter to the last. Affectionate and possessive, it stays constant through everything.
- “Mer” diminutive ch 4–54
The tender shortening. Used to ground her, soothe her, or signal intimacy without weight.
- “Meryn” given name ch 3–57
Full name reserved for concern, urgency, or emotional directness. When he says it, something is serious.
- “my queen” pet name ch 50
Appears once as her political status becomes real.
- “beloved / love” pet name ch 57
The most intimate names arrive last, but the context is manipulation. He’s stealing her power while he says them.
Two Catherines → Heathcliff
- “Heathcliff” given name ch 3–15
Cathy (the mother). Bare first name, childhood intimacy. 10 uses.
- “my Heathcliff” pet name ch 15
Cathy. Possessive, idealized—used once, in delirium.
- “Mr. Heathcliff” formal title ch 2–30
Miss Catherine (the daughter). Always formal. Generational distance.
- “uncle” pet name ch 21, 27
Miss Catherine. A brief, failed attempt at kinship.
How do you gather data like this? Let’s use AI for something other than code for a change…
The Prompt
After reading entirely too much romantasy and thinking entirely too much about how characters refer to each other, you might determine we’ll to collect a few things:
- Source: Who is speaking?
- Target: Who is being referred to?
- Phrase: What phrase was used by the source to identify the target?
- Type: Is it a diminutive, pet name, formal title, epithet, or given name?
- Context: A short description of how the phrase was used (tone, frequency, circumstances).
Fourth Wing — example tuples
| Source | Target | Phrase | Type |
|---|---|---|---|
| Xaden | Violet | “Sorrengail” | given name |
| Surname-only address from their first encounter. Authoritative, distancing. Never affectionate. | |||
| Xaden | Violet | “Violence” | epithet → pet name |
| Coined during close-contact sparring as a mocking nickname derived from her name and aggressive fighting attempts. By chapter 19 the same word is moaned intimately during their kiss. | |||
| Xaden | Violet | “Violet” | given name |
| Her actual first name, used urgently and intimately to persuade her to leave for his sake. Only appears once he is emotionally invested. | |||
| Violet | Xaden | “Xaden” | given name |
| Used repeatedly in direct address during intimate and emotional encounters. | |||
| Violet | Xaden | “Riorson” | given name |
| Used sternly the first time to order him out of the room. Later appears commandingly and playfully. | |||
| Dain | Violet | “Vi” | diminutive |
| Affectionate childhood nickname used repeatedly with concern and familiarity. | |||
| Dain | Xaden | “Wingleader” | formal title |
| Used emphatically through clenched teeth to acknowledge Xaden's position. Dain never uses his first name. | |||
| Violet | Rhiannon | “Rhi” | diminutive |
| Affectionate casual address used in squad banter, teasing, and excited moments. | |||
| Mira | Violet | “sis” | pet name |
| Used emphatically while warning Violet about the dangers of the parapet. | |||
Since we read books chapter-by-chapter, it makes sense to ask the AI to do the same, and it helps keep context windows relatively small1. We’ll feed it one chapter at a time and ask for [Source, Phrase, Target, Type, Context] tuples.
<chapter_text>{{ chapterText }}</chapter_text>
You are an AI assistant specializing in narrative analysis and character linguistics. Your task is to analyze the <chapter_text> above to identify and extract all unique identifiers (appellations) that characters use to refer to one another. Follow these instructions carefully:
Your goal is to create a structured list of appellations in the format (Source, Appellation, Target). Analyze the <chapter_text> above and follow these steps:
1. Analyze the Text: - Read the chapter text thoroughly, paying close attention to dialogue, narration, and internal monologue. - Your goal is to find how one entity refers to another using a specific name or identifier. - Focus on identifiers such as: - Diminutives (e.g., "Sam" for Samuel) - Pet names or nicknames (e.g., "sis", "buddy", "love") - Formal titles used as unique identifiers (e.g., "the Captain", "Professor") - Epithets or descriptive names (e.g., "Wise One", "the tall stranger") - Any other name-like identifier that singles out a specific character (e.g., "Elara", "Mr. Blackwood").
2. Identify Appellations: For each unique identifier you find, identify the three key components: - Source: The character that _uses_ the identifier (the speaker or thinker). You will record their name as it appears in the text. - Target: The character that is _being referred to_ by the identifier. You will record their name as it appears in the text. - Appellation: The description of the identifier itself (see step 3).
3. Define the Appellation: The appellation consists of three parts: a phrase, a type, and a context.
Phrase (`phrase`): The literal, exact string from the text that is used as the identifier (e.g., "Sam", "the Captain", "Wise One").
Type (`type`): Choose the most fitting type that best describes the identifier. Use uppercase format. Here are the valid types: - DIMINUTIVE: A shortened or familiar form of a proper name (e.g., "Sam" for Samuel, "Liz" for Elizabeth). - PET_NAME: An informal, often affectionate, name not based on the proper name (e.g., "sis", "buddy", "darling"). - FORMAL_TITLE: A rank, profession, or honorific used as an identifier (e.g., "the Captain", "Professor", "My Lord"). - EPITHET: A descriptive phrase or adjective-based name (e.g., "the Wise One", "the tall stranger", "Man of Steel"). - GIVEN_NAME: The character's standard first name, last name, or full name (e.g., "Elara", "Blackwood", "Marcus Blackwood").
Context (`context`): Write a concise, one-sentence description of the usage. This should explain the nature of its use (e.g., "Used affectionately," "Used as a formal address," "Used when angry") and note its frequency if apparent.
4. Output Format: Your final output must be a single JSON object. Do not include any text or explanations outside of this block. For each unique appellation you identify, create an object following this exact structure:
```json{ "appellations": [ { "sourceCharacterName": "[character name as it appears in the text]", "appellation": { "phrase": "[Literal phrase from text, e.g., 'Sam']", "type": "[APPELLATION_TYPE]", "context": "[Concise description of its usage, tone, and frequency.]" }, "targetCharacterName": "[character name as it appears in the text]" } ]}```
Example:
```json{ "appellations": [ { "sourceCharacterName": "Lena", "appellation": { "phrase": "Marcus", "type": "GIVEN_NAME", "context": "Used as a standard, familiar address during conversation." }, "targetCharacterName": "Marcus" }, { "sourceCharacterName": "Marcus", "appellation": { "phrase": "Lena", "type": "DIMINUTIVE", "context": "An affectionate diminutive used frequently in private, e.g., \"Lena, you can't mean it!\"" }, "targetCharacterName": "Lena" }, { "sourceCharacterName": "Kaelen", "appellation": { "phrase": "the old man", "type": "EPITHET", "context": "Used in internal monologue to dismissively refer to the Elder." }, "targetCharacterName": "Elder" }, { "sourceCharacterName": "Guard", "appellation": { "phrase": "Captain", "type": "FORMAL_TITLE", "context": "Used as a formal, respectful address of rank." }, "targetCharacterName": "Kaelen" } ]}```
Remember:
- The `phrase` value MUST be the literal, case-sensitive string found in the text.- Aggregate multiple uses of the _exact same_ (Source name, Target name, Phrase) combination. Your `context` entry should summarize the overall usage, tone, and frequency (e.g., "Used regularly, always affectionately," or "A common, neutral identifier."). Do not create duplicate entries.- Adhere strictly to the provided JSON format for your output.
Now, analyze the chapter text and produce your list of appellations following these instructions. Your final output should contain only the JSON object with appellations.Run The Prompt
Running the prompt is simple enough2. I’m using MiniMax M2.7 because it is open weights & scores well on the axis of Intelligence vs. Price. Processing novels is token intensive: Fourth Wing is ~272,393 tokens in all.
import { readFileSync } from "fs";import { join } from "path";
import Anthropic from "@anthropic-ai/sdk";import { Template } from "@huggingface/jinja";
const __dirname = new URL(".", import.meta.url).pathname;
const chapterText = readFileSync(join(__dirname, "chapter-content.txt"), "utf-8");
const templateSource = readFileSync(join(__dirname, "prompt-v1.jinja"), "utf-8");
const template = new Template(templateSource);const prompt = template.render({ chapterText });
const client = new Anthropic();
const stream = client.messages.stream({ messages: [{ role: "user", content: prompt }], model: "MiniMax-M2.7", max_tokens: 8192,});
for await (const chunk of stream) { if (chunk.type === "content_block_delta" && chunk.delta.type === "text_delta") { process.stdout.write(chunk.delta.text); }}Jane Eyre — Chapter XXVII
| Source | Target | Phrase | Type |
|---|---|---|---|
| Jane | Mr. Rochester | “sir” | formal title |
| Formal respectful address used consistently throughout. | |||
| Jane | Mr. Rochester | “Mr. Rochester” | given name |
| Standard formal address used in conversation. | |||
| Jane | Mr. Rochester | “my master” | epithet |
| Respectful designation acknowledging his authority. | |||
| Jane | Mr. Rochester | “dear master” | epithet |
| Affectionate and respectful term used when blessing him. | |||
| Jane | Mr. Rochester | “my dear master” | epithet |
| Warm respectful address used in farewell. | |||
| Jane | Jane | “my daughter” | pet name |
| Words spoken by the visionary voice/mother figure addressing Jane. | |||
| Mr. Rochester | Jane | “Jane” | given name |
| Standard address used frequently throughout the conversation. | |||
| Mr. Rochester | Jane | “my little darling” | pet name |
| Term of endearment used when expressing affection. | |||
| Mr. Rochester | Jane | “Janet” | diminutive |
| Affectionate diminutive of Jane used several times in the chapter. | |||
| Mr. Rochester | Jane | “my darling” | pet name |
| Term of endearment used when speaking intimately to Jane. | |||
| Mr. Rochester | Jane | “little Jane” | diminutive |
| Affectionate address referring to Jane's small stature. | |||
| Mr. Rochester | Jane | “my little Jane” | diminutive |
| Affectionate diminutive used when reminiscing about past encounters. | |||
| Mr. Rochester | Jane | “my hope” | pet name |
| Term of endearment expressing deep emotional attachment. | |||
| Mr. Rochester | Jane | “my love” | pet name |
| Direct expression of love used in moment of anguish. | |||
| Mr. Rochester | Jane | “little Jane's love” | pet name |
| Used when referring to Jane's affection as his desired reward. | |||
| Mr. Rochester | Bertha Mason | “my wife” | epithet |
| Used mockingly or bitterly to refer to Bertha Mason. | |||
Not bad, and that’s with a model that costs $0.3/m in, $1.2/m out ($0.06/m cached read!). The only one that stands out to me is “sir” — too generic. Let’s update the prompt to avoid results like that:
2. Identify Appellations: For each unique identifier you find, identify the three key components: - Source: The character that _uses_ the identifier (the speaker or thinker). You will record their name as it appears in the text. - Target: The character that is _being referred to_ by the identifier. You will record their name as it appears in the text. - Appellation: The description of the identifier itself (see step 3).
Exclude overly generic phrases (e.g., "sir", "the man", "the woman", "the place") and generic insults or derogatory terms (e.g., "idiot", "fool") that could refer to multiple characters. Only include identifiers that clearly and specifically refer to a single named character.The Results
Once you have all the appellations extracted (across all the chapters!), you can visualize the relationships as a directed graph:
Click a character to highlight their connections. Click two to see how they refer to each other. Drag to rearrange. Scroll to zoom.
The Typo
Running it for Fourth Wing will reveal the typo, click “Oren” & “Ridoc” to highlight it:
Click a character to highlight their connections. Click two to see how they refer to each other. Drag to rearrange. Scroll to zoom.
Extra Credit
I’ve intentionally glossed over some details which are needed to create a ‘production ready’ system:
-
Converting a book into plain text (or markdown) is not as trivial as you might think, nor is breaking it up by chapter.
-
Often novels are written in the first person, so it makes sense to include a hint of whose point of view we’re experiencing. Some tricky novels even switch the point of view mid-chapter, usually indicated by a dinkus.
-
You’ll want to provide a list of named characters for the LLM to select from, extracted separately. Otherwise, across chapters you’ll sometimes receive a source or target name of “Jane” and sometimes “Jane Eyre”. Are those the same person? That’s actually a fairly difficult question, particularly for books like Wuthering Heights which literally has two characters named “Catherine”. The answer ends up being in the chapter text itself.
Footnotes
-
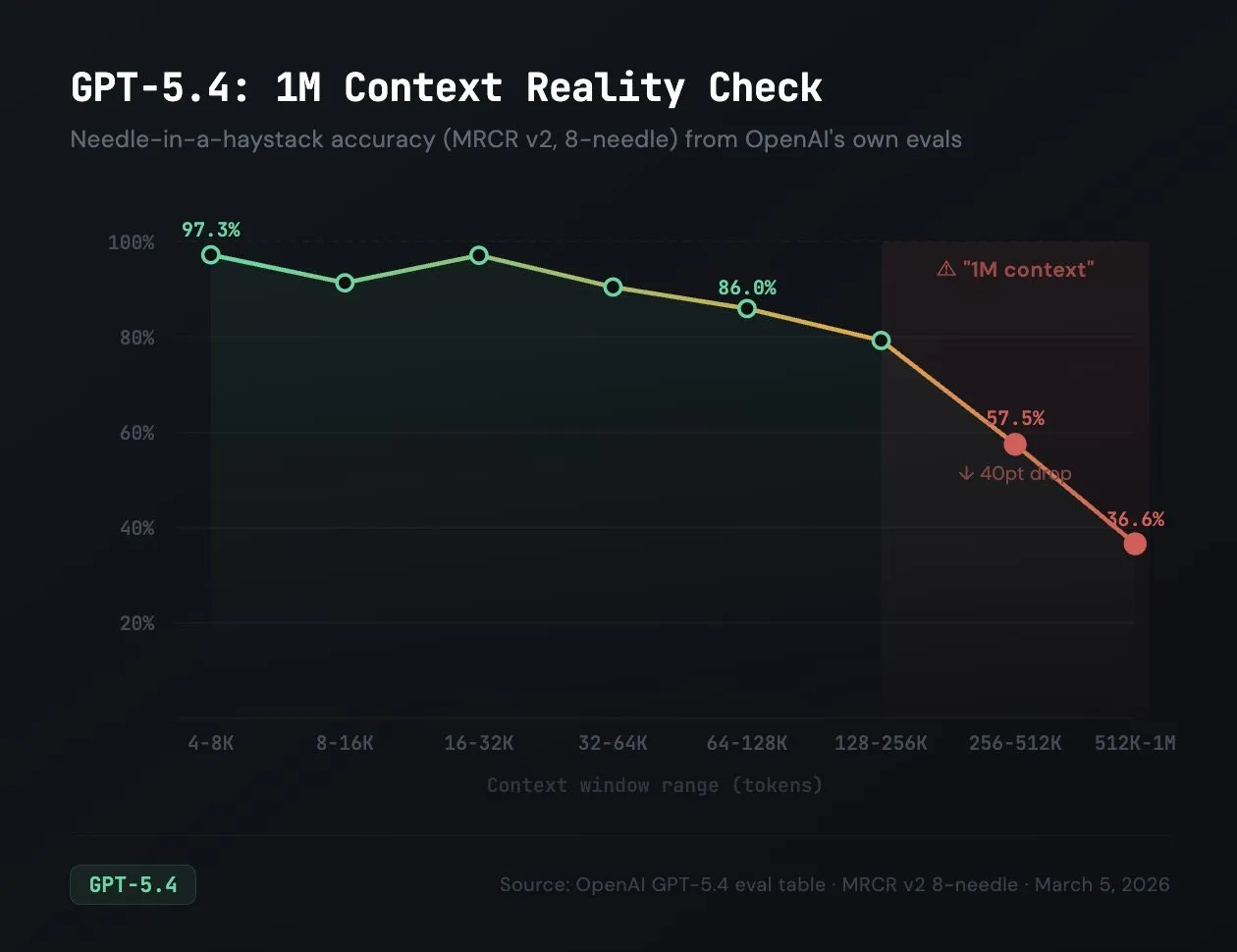
Yes, context windows are rather large at 1-2M+, but how well do they actually utilize that context window? Turns out, not very well at all:
-
If you’re running this for real, I’d recommend structured outputs. ↩